내가 무엇을 해야할지 모르겠을 때 (2)




지난번에 올렸던 내가 무엇을 해야 할지 모르겠을 때 (1)을 이은 (2)가 나왔습니다.
2탄을 올리겠다고 하고, 프로그램 개발에 빠져 안 올리고 있었습니다.
못 보신 분들은 1탄을 보고 오시면 좋을 것 같습니다.
내가 무엇을 해야할지 모르겠을 때 (1)
좋아하는 것 혹은 잘하는 것을 3가지 정도 말해 보라고 하면 즉각 대답할 수 있을까요? 저는 제가 무엇을 좋아하고 잘하는지 모르기 때문에 대답을 못합니다. 유명한 강연 / 자기 계발 채널 / TV
gold-goose.tistory.com
지금 당장 내가 뭘 해야 할지 모르겠을 때, 무엇을 해야 할까 2탄 시작합니다.
4. 성공의 방정식이 있을 거라 생각하지 마라
무슨 말이냐고요??
쉽게 말해 나에게 맞는 것이 무엇이 있을지 "검색"이나 "조언"을 구하지 않는 겁니다.
예를 들어 한창 유행하던 스마트 스토어가 돈을 많이 번다고 그게 성공의 지름길이라고 무작정 덤비지 말라는 겁니다.
대부분의 사람들이 1~2개월 하고 때려치운 후에 하지 말라고 올린 영상이 유튜브에 100개가 넘습니다.
내가 무언가에 꽂혔는지 파악하고 내 방식대로 길고 우직하게 나아가는 것이 지속 가능한 방법입니다.
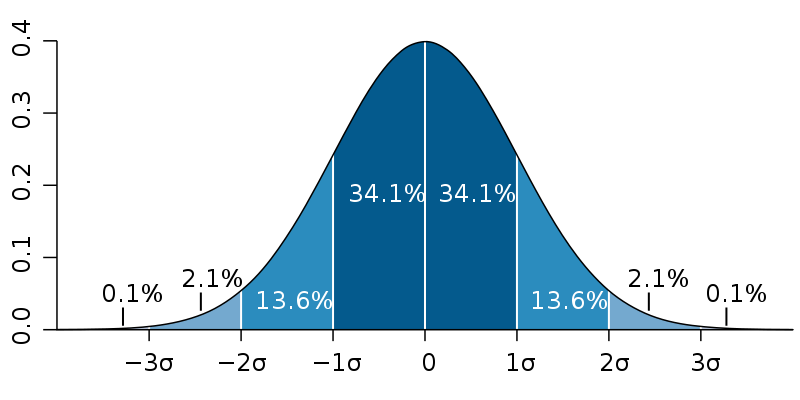
성공의 방정식이 있다면 이미 많은 사람들이 그렇게 했을 거고 대다수가 성공을 하지 않았을까요??
본인이 생각하는 성공을 '정의'하고 자신만의 '성공의 방정식'을 만들어야 합니다.
5. 혼자 여행 떠나기
해외든 국내든 집 앞이든 상관없이 혼자 여행을 떠나세요.
갈 곳을 정하는 것부터 언제 가고, 어떤 콘셉트로 갈 것인지, 가서 뭘 할 건지, 뭘 먹을 건지 정하는
모든 과정에서 설렘과 기대감은 일종의 동기부여로 작용합니다.
근데 왜 혼자 여행을 떠나라는 걸까요??
혼자 여행을 떠나야 같이 떠나는 사람을 의식하지 않고 본인에게 더욱 집중할 수 있기 때문입니다.
내가 원하는 음식, 장소가 아니라 다른 사람과 타협 후 맞춰 정해진 것들은 내가 하고자 하는 것이 아닙니다.
따라서 내가 무엇을 하고 싶은지 정확히 알려면, 온전히 나에게 집중할 수 있는 혼자 여행을 떠나는 것이 좋습니다.
혼자 여행을 떠남으로 자신과의 대화를 하는 시간을 가지는 것을 추천합니다.
6. 영어공부
절대로 토익, 토플을 공부하라는 것이 아닙니다.
뭐 하겠다면 말리지는 않겠지만, 내가 필요를 느끼는 영어를 공부하라는 말입니다.
가수 김종국이 말하길 영어공부 도대체 뭐부터 할지 모르겠다면
자기소개를 영어로 할 수 있을 정도를 목표로 영어 공부를 하라고 했습니다.
예를 들어 나의 헤어스타일이 어떻고, 잘 땐 어떻게 자는지, 영화는 어떤 장르 영화가 좋은지를
누가 물어보면 바로 영어로 답할 수 있을 정도로 말할 수 있는 수준을 목표로 하는 거죠.
심지어 이 방법은 나를 알아가는 효과도 있습니다
제가 추천하는 방법은 크게 두 가진데요.
'스마트폰 설정을 모두 영어로 하기'와 '검색할 때 영어로 하는 습관 기르기'입니다.
거창하게 영어 기사나 논문을 읽는 것도 물론 도움이 되겠지만, 금방 지치기 마련입니다.
일상에 영어를 접하게 하는 것이 가장 중요한데요.
간단하면서도 자주 접하는 것이 스마트폰이기 때문에 위 두 가지 방법은 영어공부에 큰 도움이 됩니다.
7. 자필로 쓴 일기를 되돌아보기
마지막으로 내가 뭘 해야 할지 모르겠을 때 추천하는 방법은 '자필로 쓴 일기를 되돌아보기'입니다.
저는 이 방법을 매일 하고, 가장 먼저 이 방법을 사용합니다.
저는 일기에 내가 무슨 생각을 했고, 어떤 걸 하면 좋을지, 좋은 사업 아이템은 뭐가 있을지
생각날 때마다 하나도 빠짐없이 다 적어 둡니다.

물론 이 방법은 나의 메모 습관과 일기 습관이 잘 잡혀있어야 가능한 방법이지만, 지금부터라도
메모 습관과 일기 습관을 길러 나간다면 분명 큰 도움이 될 거라 생각합니다.

여기서 더 나아가 '내가 언제든지 메모할 수 있는 환경을 만들기'도 내가 무엇을 해야 할지 모를 때 좋은 방법입니다.
컴퓨터를 자주 사용하는 분들은 윈도의 스티키 노트를 바탕화면에 항상 켜 둔다거나,
스마트폰을 자주 사용하는 분들은 카카오톡의 내게 보내기에 메모를 남기면 메모 습관을 기르기 좋습니다.

제가 지금까지 올린 7가지 방법을 모두 했다면, 지금 당장 내가 뭘 해야 할지 감이 잡힐 겁니다.
세상에는 의외로 내가 하고 싶어하는 것이 많습니다.
내가 잘 알지 못할 뿐!
'Deep Breath' 카테고리의 다른 글
| 5초만에 모든 일을 긍정으로 바꾸는 방법 (261) | 2023.01.07 |
|---|---|
| [자기개발] 내가 무엇을 해야할지 모르겠을 때 - 해야 할 3가지 (74) | 2022.12.31 |
| "객관적이다"라는 것이 가능한 말일까?? (222) | 2022.08.24 |