



[Skewness Volatility] 왜 떨어짐은 크고, 상승은 작은가?
Quant2022. 9. 20. 23:29




반응형
시장이 Bear market으로 형성되면 주가가 급하게 떨어지는 모습을 자주 볼 수 있다.
이는 시장의 심리적인 요인이 아주 크게 작용한다.
이러한 현상으로 인해 풋옵션의 프리미엄이 콜옵션의 프리미엄보다 커지게 되고,
"Skewness Volatility" (변동성의 비대칭성)이 나타난다.
간단한 프로젝트로 QQQ의 변동 데이터를 통해 실제로 주가의 상승 폭보다, 하락 폭이 큰지 직접 확인해 보려한다.
1. 데이터 구하기
QQQ의 가격 데이터는 Investing 사이트에서 제공하는 csv 파일을 사용하였다.
근 5년간의 데이터를 사용하였다.
인베스코QQQ ETF 과거 데이터 - Investing.com
인베스코QQQ(QQQ)ETF历史数据一览,包括인베스코QQQ(QQQ)ETF历史行情,年化收益率,每日净值和涨跌走势图表。
kr.investing.com
data.csv
0.01MB
2. 데이터 전처리
근 5년간의 데이터를 사용하려고 보니, 이 기간은 대세 상승장이었고,
하락 값과 상승 값의 비율이 전혀 맞지 않았다.
따라서 V자 반등 구간의 데이터만 사용하였다.
또한, Skewness의 모습을 최대한 나타내기 위해 약보합 +-0.3% 이내의 구간인 날들은 데이터 프레임에서 제거하였다.
# 기존 index를 제거
df.set_index('date', inplace=True)
# 현재 -> 과거 순에서 과거 -> 현재 순으로 바꿔줌
df = df.iloc[::-1]
# '%'가 있어 변동 값을 str값으로 인식하므로 %를 제거 후 숫자형으로 변환
df['volatility'] = df['volatility'].str.replace('%', '')
df['volatility'] = pd.to_numeric(df['volatility'])
# -0.3 ~ 0.3% 수준의 보합은 제거
condition = df[ (-0.3 < df['volatility']) & (df['volatility'] < 0.3)].index
df = df.drop(condition)
a = df.loc[condition, 'volatility'].count()
b = df.loc[~condition, 'volatility'].count()
print("하락한 날의 수는",a ,"개", "상승한 날의 수는",b ,"개 입니다.")
3. 분포 확인
import matplotlib.pyplot as plt
import matplotlib.ticker as ticker
plt.figure(figsize=(20,8))
ax = plt.subplot()
ax.xaxis.set_major_locator(ticker.MultipleLocator(16))
ax.yaxis.set_major_locator(ticker.MultipleLocator(2))
ax.yaxis.set_minor_locator(ticker.MultipleLocator(0.5))
plt.scatter(df.index, df['volatility'], color=df['color'])
plt.xticks(rotation=45)
plt.grid(True)
# y축 범위 설정
plt.ylim(-12,12)
plt.show()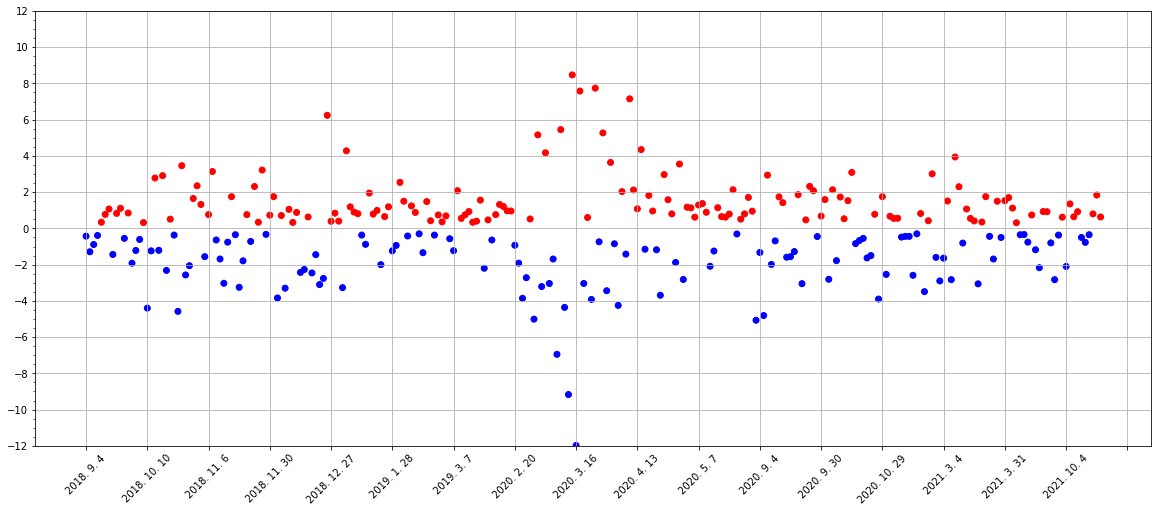
4. 히스토그램
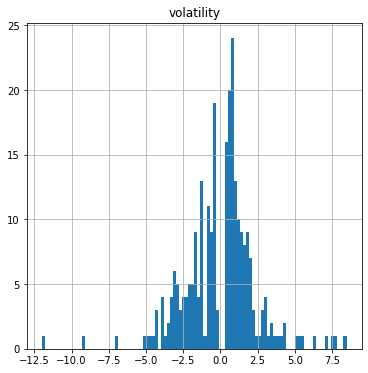
df.hist(bins=120, figsize=(6,6))+- 1% 구간을 제외하고는 확실히 그래프가 right skewed 임을 확인 할 수 있다.
히스토그램이 밋밋한 부분은 시각화를 더 공부하면서 극복해보도록 하겠다.
메인 질문 "왜 떨어짐은 크고, 상승은 작은가?" 에 대한 답은 추후에 글을 쓰도록 하겠다.
반응형
'Quant' 카테고리의 다른 글
| [금융상품] 원자재 투자의 대표 산업 금속과 선물거래 특징 (0) | 2022.09.28 |
|---|---|
| [Project] 주식을 몇 시에 매수하는 것이 가장 좋을까?? (1) | 2022.09.23 |
| [금융 상품] 달러의 역사 - 미국이 기축통화 지위를 버릴 수 밖에 없는 이유 (월가아재) (38) | 2022.09.07 |
| Finance 참고 블로그 (27) | 2022.03.20 |
| [Quant Strategy] NCAV 전략 - 2022.03.16 기준 (12) | 2022.03.17 |
댓글()
